Was Siri aus dem Gehirn über Tuning, Lärm in einem überfüllten Raum lernen können

Gehen Sie in einen Raum voller Menschen, und Ihr erste Eindruck ist nur Rauschen. Innerhalb von Sekunden starten Sie Wörter, Phrasen und Fragmente von Gesprächen herausgreifen. Bald werden Sie fröhlich mit Freunden, blind gegenüber den Lärm um Sie herum im Chat sein. Aber die meisten von uns nie aufhören um zu denken, genau wie unser Gehirn es schafft, eine Konversation Thread inmitten der lauten Hintergrund in einem überfüllten Raum herausgreifen.
Es nennt sich "cocktail-Party-Effekt". In einem jüngst veröffentlichten Papier in PLOS Computational Biology, Forscher an der University of Tokyo, unter der Leitung von Takuya Isomura, berichten, dass das Geheimnis in das Gehirn bemerkenswerte Fähigkeit, sich schnell selbst rewire liegt – eine Eigenschaft, die sogenannte Plastizität. Einzelnen Gehirnzellen (Neuronen) können tatsächlich erfahren Sie, wie viele Arten der Eingabe auszublenden und konzentrieren sich vor allem auf einen ermöglicht es uns, ein sinnvolles Gespräch auch in der Mitte eine laute Bar haben.
Es ist bekannt, dass das Gehirn Synapsen als Reaktion auf unsere Erfahrungen ständig Neuverkabelung ist. Aber wie Emilie Reas in PLOS Blogs Netzwerk ausgeführt hat, "Isomura und Kollegen zufolge zum ersten Mal Neuronen aufgerufen werden können diese Lernmechanismen zu erkennen und Informationen zu unterscheiden." Diese Art von Arbeit könnte eines Tages nützlich sein, für die Verbesserung der Spracherkennungs-Software – wie Siri, Wer ehrlich Art von saugt an Geräusche herausfiltern – akustische Sensorik, und vielleicht sogar hören, Aids und Cochlea-Implantate.
Der Filtervorgang ist viel komplizierter als nur Erkennung klingt, da das Gehirn auch Dinge wie Direktionalität, visuelle Hinweise und zeitlichen Muster der Rede verarbeitet wird. Zum Beispiel studieren eine 2013 verwendeten Magnetoenzephalographie (MEG) imaging um zu messen, ob visuelle Signale wie Mimik, uns helfen können, "Vorhersagen", was wir hören. Die Forscher fanden heraus, dass Probanden eine individuelle Unterhaltung gut folgen konnte, und kämpfte ein bisschen mehr zu bleiben in einer cocktail-Party einstellen – wie wir alle. Aber sie viel besser auf die letztere Aufgabe durchgeführt, hätten sie ein Gesicht zu gehen zusammen mit der Rede-Muster.
Die Verarbeitung kommt auf Tonnen von elektrischen Signalen, die Reisen in das weitläufige Netz von Neuronen im Gehirn, so natürlich Neurowissenschaftler sind daran interessiert, mehr über die genauen Mechanismen von denen dies geschieht. Seit mehreren Jahren können Shihab Shamma von der University of Maryland, College Park, vorgeschlagen, dass der cocktail-Party-Effekt das Ergebnis der Hörnerv Zellen so anpassungsfähig sind sie schnell "sich auf bestimmte Geräusche konzentrieren umzustimmen". Als ich wieder im Jahr 2011 schrieb:
Es ist Art von eine auditive Feedback-Schleife, die uns zu sortieren, verwirrend eingehende akustische Reize ermöglicht. Er ist überrascht, aber, wie schnell dieser Prozess geschieht: auditive Nervenzellen im Erwachsenen Säugetier Gehirn machen die Anpassung in wenigen Sekunden. Zu Bernd deutet dies entwickelte Gehirn sogar noch "Kunststoff" oder anpassungsfähig als bisher realisiert. Wir sind buchstäblich unser Geist verändert.
Bernd hat weiterhin diese Art von Veränderungen im Gehirn zu studieren. Und eine weitere 2013 Studie starke Unterstützung für seine These durch die Erfassung dieser schnelle Anpassung in Aktion mit einem implantierten Electrocorticography Aufnahmegerät. Wenn wir unsere Aufmerksamkeit auf eine Person die Rede in einem lauten Raum konzentrieren, wird diese Person Stimme die Informationsprozesse im Gehirn dominieren.
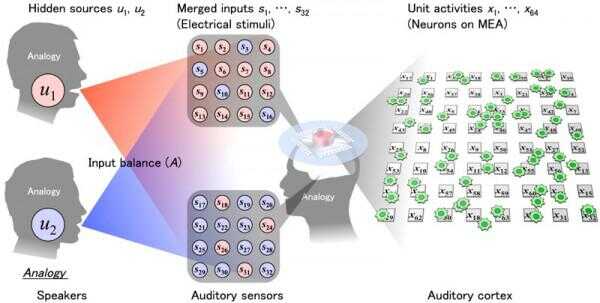
Die neuesten Tokyo-Studie liefert mehr Beweise für diese bemerkenswerte Plastizität. Die Forscher die elektrische Aktivität in eine Schüssel mit kultivierten Rattenneuronen aufgezeichnet, dann gezappt Zellen mit elektrischen Impulsen in zwei bestimmten Mustern, mit dem Ziel, die Mischung der Stimmen, die man auf einer Cocktailparty auftreten zu simulieren. Sie taten dies über 100-Mal den Reiz unterschiedlicher Muster, so sie verfolgen konnte, wie die Neuronen verändert ihre Reaktion auf den Reiz.
Etwa "gelernt halbe Neuronen schnell" auf ein Eingabemuster konzentrieren, während die andere Hälfte gelernt, auf das andere Muster zu konzentrieren. Diese Einstellung beibehalten wie einen Tag später auch in Neuronen, die nur kurz auf die Reize ausgesetzt waren. Die Tokyo-Team sogar einen möglichen Mechanismus lokalisiert: NMDA (N-Methyl-D-Aspartat-)-Rezeptoren im Gehirn, die für die Plastizität der Synapsen im Gehirns sowie die langfristige Gedächtnisbildung entscheidend sind. Wenn diese Rezeptoren blockiert, zeigte der kultivierten Rattenneuronen fast keine Präferenz für ein Eingabemuster übereinander.
Programmierung eines Computers zu tun, was das Gehirn so leicht vollbringt erweist schwierig. Der Cocktailparty-Effekt wird das "cocktail-Party-Problem." Das ist wegen der Vielzahl der möglichen Klangverbindungen in Rede.
Nur der Klang der Stimme einer Person setzt sich aus vielen unterschiedlichen Frequenzen, die in ihrer Intensität variieren. Ihre typische Spracherkennungssystem wie Siri, wirkt ein wenig wie Autokorrektur: Es wird brechen, was auch immer Sie sich in Phoneme, die einzelnen Einheiten sagst, die Wörter bilden. Diese Phoneme auftauchen als bestimmte Muster in akustischen Spektrogramme. Das Programm berechnet dann die Wahrscheinlichkeit, einen bestimmten Ton ("oh"), gefolgt von einer anderen ("de"). Und genau wie Autokorrektur, Spracherkennungs-Software oft falsche Vermutungen.
Bessere Algorithmen können helfen. Im Jahr 2011, Wissenschaftler am IBM TJ Watson Research Center erstellt einen Algorithmus, der die cocktail-Party-Problem lösen könnte, durch die Konzentration auf die dominante Lautsprecher – Wer ist sprechen (oder vielleicht schreien) am lautesten. Gerade im vergangenen April Gebrauchtmaschine Wissenschaftler an der University of Surrey in England ein Deep Learning, um menschliche Stimmen aus dem Hintergrund in einer Vielzahl von Songs zu trennen. Und im August letzten Jahres, Duke University Wissenschaftler gebaut erfolgreich ein System in der Lage, nahezu perfekte Genauigkeit (96,7 Prozent), wenn mit der Unterscheidung zwischen drei überlappende Schallquellen beauftragt.
Es ist immer noch eine viel einfachere Aufgabe als Filterung der unzähligen konkurrierenden Stimmen auf Ihre durchschnittliche Cocktailparty. Aber es ist ein guter Start.
[PLOS Computational Biology über PLOS Blogs Netzwerk]
Bilder: (von oben) Gizmodo / Isomura, R. Et Al. (unten) / PLOS Computational Biology

9 Dinge, die Sie über die Mutterschaft während weg von Ihren Kindern lernen können

Was wir aus dem Fernsehen am Wochenende gelernt: Graham Norton und Eurovision Regel oberste

Austritt: Lehren aus dem Osten über welche Torheit wäre es isoliert zu wählen

Was kann dieser Papagei In 2 Minuten wird Schlag jedes Haustier machen, was Sie aus dem Wasser
7 Personen, die brauchen, um aus dem Freaking Weg

6 mind-blowing Dinge, die vor kurzem aus dem zweiten Weltkrieg entdeckt

Du wirst nicht glauben, was dieser Kerl hat ein berühmtes Gemälde - oder was passiert nach

Aus dem Archiv, 23. Januar 1965: David Niven auf die goldenen Zeiten von Hollywood

Was sagt Ihr Lieblingsgetränk über Sie

NASA Orbiter wird Watch Neuanlagen Photosynthese aus dem Weltraum
Karibische Meer "Pfeifen neugierig" aus dem Weltraum erkannt
7 bizarre Klänge aus dem Weltraum

Erstes Foto der Erde aus dem Weltraum schnappte 45 Jahre vor
