Brewster es Billionen: Internet Archive ist bestrebt, Web-Geschichte lebendig zu halten
Unbezahlbare Schatz von Bytes zielt darauf ab, Websites zu speichern, die ansonsten – verloren gehen könnten, alle aus einem Vorort San Francisco

Im Zeitalter der Informationsüberflutung und Ephemera, wo eine Online-Sensation alle fünf Minuten dauern kann, breitet sich Wort, dass das Internet ein Gedächtnis hat, und sein Name nicht Google ist.
Noch überraschender war, hat es eine physische Adresse: 300 Funston Avenue, Richmond, San Francisco. Es ist eine verschlafene, unscheinbare Straße, bis Sie kommen, eine imposante, neoklassizistische Gebäude mit griechischen Säulen, Heavy-Metal-Türen und eine Fahne der Welt auf dem Rasen gepflanzt.
Treten Sie ein, und das erste, was, das Sie sehen, an der Rezeption, ist ein Haufen neu gelieferten Kisten mit Festplatten, jedes fähig zur Speicherung von 4 Billionen Bytes an Informationen. Summende Geräusch eine Treppe hinauf zu folgen und Reihen von Maschinen auftreten, Lichter blinken, methodisch Staubsaugen der Menschheit wissen. Dies ist das Internet-Archiv.
"Unsere Mission ist es universellen Zugang zu allen Informationen die ganze Zeit," sagte Rick Prelinger, Präsident des Verwaltungsrates. "Wir sind Teil der Infrastruktur des Internets. "Wir sind das Web Speicher."
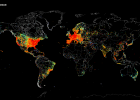
Das Internet Archive, einer gemeinnützigen Organisation ist das digitale Äquivalent zu der alten Bibliothek von Alexandria, eine aufkeimende Hort von Websites, Video, Film und Musik, die sonst verloren gehen könnten. Es hält derzeit 281bn Webseiten oder URLs, und jeden Monat fügt Milliarden mehr. Außerdem erfasst und speichert Kabelnachrichten, Bücher, Zeitschriften und YouTube-Clips. Lange von Wissenschaftler, Techniker und Bibliothekare verehrt, breitet sich das Archiv Ruhm nun unter den gewöhnlichen Menschen, Zeichnung mehr als tausend Zugriffe pro Sekunde auf seiner Website. Viele, jedoch nichts von seiner Existenz, und da gab er eine Tour an der Erziehungsberechtigten, Prelinger sagte:
Ich bin sehr überrascht, dass es nicht mehr Internet Archive gibt. Es ist das Medium unserer Zeit, aber es gibt ein Ethos der Ahistoricity. Wir versuchen das negieren.
Die Organisation, die 1996 von Brewster Kahle, Internet-Pionier und Unternehmer, mitgegründet wurde hält seine Mission immer dringender werden. Technologische, wirtschaftliche und politische Druck verschlingen digitalen Informationen wie Termiten, die – einmal die "Zähne der Zeit" genannt – durch antike Bibliotheken chomped. Festplatten verblassen und verziehen, Informationen zu zerstören. Unternehmen gehen pleite, oder entwickeln und dabei vergossen, viel, wenn nicht alle ihre digitalen Archiven. Regierungen und Institutionen wie Informationen löschen, die unangenehm oder peinlich, 404 Fehlermeldungen zu verlassen, wo einst wird waren Seiten.
"Während der Irak Krieg [Bush] weißen Haus nahm leise hinunter etwas von seiner früheren Pressemitteilungen." Aber wir hatten sie,"sagte Prelinger, dessen Spezialität ist Film Archivierung. "Digitale Informationen sind Teil unseres kulturellen Erbes, aber es ist enorm volatil. "Es ist zerbrechlich." Speichern ist nicht nur ein Akt der Denkmalpflege, sagt er, sondern ein Mittel, um Institutionen zur Rechenschaft ziehen. "Wir wollen helfen, halten Sie im Internet, ehrlich und sicher und es aus Unwissenheit zu verteidigen."
"Philosophische Verbündeten"

Philosophischen Verbündeten zählen www.wikimedia.org, Mozilla, die freie Software-Gemeinschaft, der Electronic Frontier Foundation, ein digital-Rights-Interessengruppe und der Internet-Aktivist Aaron Swartz, bis zu seinem Tod im Januar.
Google ist nicht auf der Liste. Es ist ein Wunder, sagte Prelinger, sondern kippt Suchergebnisse. "Seine Algorithmen sind nicht öffentlich. Wir wissen nicht, warum wir sehen, was wir sehen, und wir wissen nicht, was wir nicht sehen. Google kennt Ihr Profil und entsprechend angepasst. Sie wollen anzeigen zu verkaufen. Wir sind nicht Google. "Wir sind eine Bibliothek."
Personal eine Party veranstaltet im Oktober letzten Jahres einen Meilenstein feiern:-entspricht etwa 10 Milliarden Bücher – 10 Petabyte archiviert. Bibliothekaren und Wissenschaftlern das Archiv Arbeitnehmer als "Helden" und "Rockstars" Beifall, aber die Bediensteten sind wahrscheinlicher, sich Geeks und Nerds zu nennen. Sie scherzen über Kilowatt Verbrauch und Meta-Daten-Replikation. Einige nehmen Teil ihres Gehalts in Bitcoin und haben überzeugt der benachbarte chinesischen Restaurant, die Währung zu akzeptieren. Es gibt eine wachsende Schar von halber Größe Terrakotta Statuen Arbeitnehmer mit mehr als drei Jahren im Betrieb. Die Wayback Machine, eine durchsuchbare Online-Museum von Milliarden von Webseiten aus dem Jahr 1996 ist benannt nach einem Segment in der Rocky und Bullwinkle Zeichentrickserie.
Kahle, ein Informatiker, ein Vermögen in den 1990er Jahren mit Tech Ventures machte, einschließlich Alexa Internet, träumte davon, eine große Bibliothek von Alexandria 2.0, da er am MIT studiert. Das Archiv erste Hauptsitz war in der nahe gelegenen Presidio Bezirk. Im Jahr 2009 zog es in einer ehemaligen Kirche der christlichen Wissenschaft in Funston Avenue; seine Säulen und Fassade erinnern an antike.
Etwa 50 Mitarbeiter arbeiten hier und weitere 100 an anderer Stelle in der Bay Area und in 32 scanning Center, in der Regel in Bibliotheken auf der ganzen Welt. Die Zentren digitalisieren Bücher, Mikrofilm und regelmäßige Film. Automatisierung erwies sich als ungenau, so dass es manuell, jede Arbeitskraft, die Verarbeitung von 800 bis 1000 Seiten pro Stunde erfolgt. Diese Arbeit bedeutet Material wie John Adams Library in Boston, der Hoover-Archiv und die 1930 uns Volkszählung sind jetzt online und kostenlos. Institutionen wie Behörden, Bibliotheken und Universitäten, viele außerhalb der USA, bescheidene Gebührenpflicht für Sonderwünsche.
Das Archiv hat 750.000 tatsächlichen Bücher in einem nahe gelegenen klimakontrollierte Lagerung auch gespeichert-Einheit, eine literarische Äquivalent des Svalbard global Seed Vault. Es gibt Platz für eine weitere 780.000.
Ingenieure kriechen"" weltweit besten Millionen Websites, Abscheidung und Speicherung von Seiten, die auf andere Seiten verlinken, die erfasst und gespeichert werden. Alle drei Monate beginnen sie, weil die Liste der Top-Millionen Websites ständig ändert. Eine durchschnittliche Webseite dauert 75 Tage. Im Jahr 2009 fuhr sie gegen die Uhr zu sparen so viel wie sie von der Web-Hosting-Dienst GeoCities, könnte bevor Yahoo es heruntergefahren. Wenn der Besitzer einer nicht mehr existierenden Website zieht es vor, dass die Seiten tot bleiben, kann er oder sie bitten das Archiv zu entfernen, Anfragen, die fast immer gewährt werden.
Ingenieure auch Nachrichten von mehr als 60 TV-Stationen weltweit und YouTube-Videos erfassen, erwähnt, letztere nach Twitter auswählen. "Es ist nicht perfekt aber Tweets geben uns eine Vorstellung davon, was Menschen wichtig," sagte Alexis Rossi, der Web-Sammlungen-Manager. Sie schätzt, dass die 10 Mrd. URLs gespeichert jeder jeden drei-Monats-Zyklus – sehr, sehr grob – etwa 10. Ausgabe im Internet vertreten:
Es ist eine Sisyphusarbeit. Wir wissen, dass wir nie alles bekommen. Im Web durch seine Natur ist unendlich.
Das Archiv drei Buchtbereich Rechenzentren verwenden 180 Kilowatt, das Äquivalent von 45 Häusern, um Server und halten die Lichter auf. Neue Festplatten halten 4 Billionen Byte, im Gegensatz zu früheren Modellen stattfindenden 2 oder 3 Billionen, hilft das Archiv Schritt zu halten.
"Ich bin stolz, dass wir alle dabei halten. Wir tun es auf einem Shoestringetat", sagte Jim Shankland, Betriebsleiter. "Solange wir unsere Arbeit machen, werden die Bytes für immer und ewig leben."
Das Internet-Archiv ist mit einem wunderschönen neuen Design erwachsen

Jamie Oliver ist bestrebt, seine Familie enger zu halten

Russland ist ein Verbot des Internet-Archivs und tadeln es auf Terrorismus

Digitales Archiv ermöglicht Web-Surfer Reisen zurück in die Zeit

Das Internet-Archiv Scan-Center wurde durch Feuer zerstört worden

Ein Blick hinter die Kulissen des Internet-Archivs unmögliche Aufgabe

Das Leben von einem Ex-Hacker, der jetzt für die Nutzung des Internets untersagt ist

Das Internet-Archiv kostenlos Online Arkade bietet Ihnen über 900 Spiele

Jason Segel, von Muppets zu Sex-Tape: "Mein Ziel ist es, durch Angst zu Fuß halten"

Oktober ist National Mobbing Awareness Month: Wie halten Sie Ihre Kinder sicher auf Facebook

Ben Whishaw und Jim Broadbent auf London Spy: "Es ist keine schwule Geschichte. Es geht um Jungs, die geschehen, Homosexuell zu sein "

Comcast ist in Web-Seiten an seinen öffentlichen Hotspots anzeigen rechts injizieren.

Mehr als die Hälfte der Internet-Verkehr ist nur Bots