Neue Datenanalyse deutet darauf hin, dass nur sechs Buch Grundstücke vorhanden
Jeder, der insgeheim dachten, dass alle Romane die gleiche Handlung haben kann durch neue Forschungsergebnisse unterstützen diesen Verdacht bestätigt fühlen. Art von.
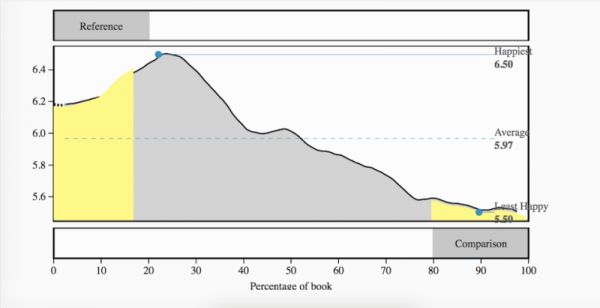
Forscher aus der Computational Geschichte Lab an der University of Vermont in Burlington verwendet Sentiment-Analyse – oder Analyse von Emotion in einer Reihe von Wörtern – das Grundstück von mehr als 1.700 Werke zuordnen. Mit Blick auf wie der emotionale Ton einer Geschichte von Moment zu Moment verändert, sehen die Forscher konnten insgesamt emotionalen Bogen der Geschichten.
Sie fanden, dass es sechs wichtigsten sind:
- Herbst-Rise-Fall, wie König Ödipus
- Aufstieg und dann ein Fall, wie was mit den meisten Schurken passiert
- Herbst und dann ein Aufstieg, wie was mit den meisten Superhelden passiert
- Stetig fallen, wie in Romeo und Julia
- Stetig steigen, wie in einem Tellerwäscher-zum-Millionär-Geschichte
- Aufstieg-Herbst-Anstieg, wie Cinderella
Innerhalb dieser allgemeinen Formen natürlich gab es viele Mini-emotionale Bögen. Die beliebtesten Geschichten folgen die "Herbst-Rise-Fall" und "Rise-Fall" Bögen, die erklären könnten, wie Superhelden-Filme und griechischen Tragödien weiterhin so liebenswert. Die Forscher selbst erstellt eine Website, wo Sie Blick auf die genaue Diagramme der Bücher, die sie analysiert.
Diese Arbeit ist kaum neue, sehen wie literarischen Theoretiker haben versucht seit Jahrhunderten um herauszufinden, wie viele Grundstücke dort wirklich sind. Im Jahre 1849 erklärte der französische Kritiker Georges Polti, gab es "36 dramatische Situationen." In den 1910er Jahren wie Wissenschaftler Vladimir Propp, ein russischer Folklorist, reiste viel und Karrieren Diagrammerstellung der Märchen die grundlegenden Grundstücke gebaut. Seitdem Volkskundler diese Arbeit formalen Systemen wie dem Aarne-Thompson Klassifizierungssystem eingebaut. Und im Jahr 1995, Kurt Vonnegut hielt einen Vortrag, wo er zog "die Formen der Geschichten" auf einem Brett und sagte, dass er glaubte, sie "Computer eingespeist werden könnte."
Natürlich hatte keiner dieser Menschen die Data Mining-Techniken, die die Burlington-Forscher haben, aber ihre Arbeit noch mit einer Prise Salz sowie genommen werden sollte. Zunächst analysiert sie nur 1.700 Stück Fiktion, die für den Zustand der Literatur kaum repräsentativ ist. Zweitens handelte es sich um alle englischsprachige Geschichten, die von Project Gutenberg mindestens 150 mal was bedeutet heruntergeladen hatte, dass sie alle in die Public Domain und nicht zeitgenössische Werke waren. Es ist wahrscheinlich, dass die Ergebnisse unterschiedlich sein würde, wenn sie auf nicht-englischen Literatur oder neuere Literatur erweitert hatte.
Die Bögen selbst sind so breit, dass Sie fast auf der Hand, und es kann schwierig sein zu unterscheiden, die man zu verwenden. Sicher, Romeo und Julia als einen stetigen Niedergang gesehen werden kann, aber es war auch kein Anstieg Wenn sie einverstanden sind, zusammen zu sein? Es ist interessant, Daten sichern die Arbeit von so vielen Gelehrten haben – solange niemand das bedeutet nimmt, sie müssen immer nur sechs Bücher zu lesen.

Diese neue Entdeckung deutet darauf hin, dass Leben auf der Erde enden könnte vor April über

Neue Daten deuten darauf hin, dass Sie nur fünf enge Freunde haben

Migrationspolitik der EU deutet darauf hin, dass Europa über die Realität Kraftmenschen bevorzugt

Ballplayer Statue deutet darauf hin, dass Sport im alten Mexiko groß waren

Wissenschaftler entdecken Wasser im Stardust und es deutet darauf hin, dass wir nicht alleine sind

Bonos Plan zur Bekämpfung der Isis mit Komiker deutet darauf hin, dass er die Handlung verloren hat

David Cameron deutet darauf hin, dass Verteidigungsminister über der Türkei liegt EU-Beitritt

Neue Berichte deuten darauf hin, Dass Bethenny Frankel ist nicht so reich wie du denkst: Bethenny reagiert Via Twitter

Umfrage deutet darauf hin, dass Privileg ist Schlüssel zur Landung Praktika

MH17 Bericht deutet darauf hin, dass Anstrengungen unternommen wurden, um die Ursachen der Katastrophe zu vertuschen

Wissenschaft deutet darauf hin, dass "Der Hund" nicht vorhanden ist (Op-Ed)

Sheriff deutet darauf hin, dass Beyoncé-Super Bowl-Show zu Angriffen auf die Polizei verbunden ist

Ashley Cole deutet darauf hin, dass seine Chelsea-Karriere vorbei nach acht Spielzeiten ist
