Physiker entdecken Sie den Aufstieg und Fall der Wörter
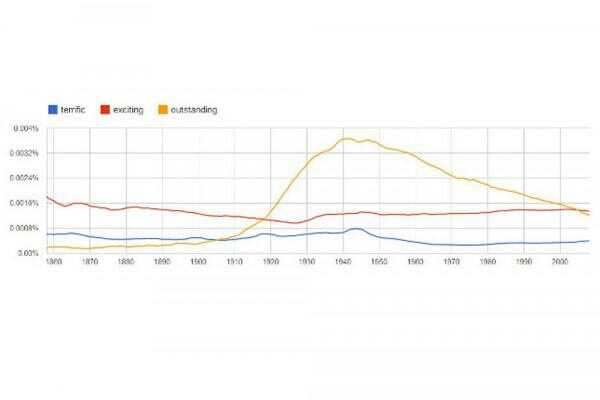
(ISNS)--jedes Jahr das Oxford English Dictionary erweitert, frisch geprägte Begriffe wie "Bromance" Einbeziehung "Staycation" oder "Frenemy." Allerdings hat eine aktuelle Analyse festgestellt, dass eine Sprache im Laufe der Zeit wächst, es mehr Satz auf seine Weise wird. Werden immer neue Wörter hinzugefügt, laut dieser Studie, aber nur wenige werden am meisten benutzt und Teil der Standardvokabular.
"Es gibt eine Menge neuer hip Wörter, die Art von herausspringen, aber die Popularität und die Lebensdauer dieser Wörter sind sehr kurz," sagte Matjaz Perc, Physikprofessor an der Universität Maribor in Slowenien und einer der Autoren des Papiers. "Unsere Studie zeigt, die wir nicht wirklich brauchen, so dass die Laufleistung, die wir von ihnen bekommen sehr gering im Vergleich zu anderen Wörtern."
Google hat mehr als 20 Millionen Bücher oder etwa 4 Prozent aller Bücher, die jemals in neun Sprachen veröffentlicht gescannt, und jeder mit einem Internetanschluss zugänglich gemacht. Es ist dieser Online-Datenbank, die die Forscher untersucht. Die Ergebnisse wurden in Nature Scientific Reports veröffentlicht.
Die Google-Datenbank enthält Bücher in den 1500er Jahren geschrieben, aber das Team begrenzt seine Forschung der letzten zwei Jahrhunderte. Sie verfolgt die Verbreitung von Wörtern in der gesamten Bibliothek mit Googles Ngram Viewer, um die Wachstum und Verbrauch Muster von Wörtern in einer anderen Sprache zu studieren.
"Dieses Projekt Google Books dieses riesige Plattform um dies alles auf einmal zu tun hat", sagte Alex Petersen, Physiker am IMT Lucca Institute for Advanced Studies in Italien und Hauptautor des Papiers.
Das Team sagt, dass das "Kern-Lexikon" der englischen Sprache von etwa 30.000 Wörtern besteht, die häufiger als ein Wort in 1 Million auftauchen. Gibt es auch ein Körper 100 Mal so groß, selten verwendete Wörter, die für die überwiegende Mehrheit der neuen Wörter gilt. Einige der wenigen, die aus der selten verwendete Kategorie in die Kern-Lexikon in den letzten Jahren sprang wurden Wörter wie "e-Mail" oder "Google." Das sind aber die Ausnahme, nicht die Regel.
"Wir nicht kommen mit neuen Farbnamen oder Beschreibungen für Dinge, die wir bereits festgestellt haben,", sagte Petersen. "Viele neue Wörter, die wir sehen sind im Zusammenhang mit Computern."
Zu Beginn des 19. Jahrhunderts weniger neue Wörter wurden eingeführt, als jetzt, aber ihre Popularität von Jahr zu Jahr dramatisch verändert. Ein Wort wie "Papier" in der oberen möglicherweise tausend am häufigsten verwendeten Worte ein Jahr und dann Drop-off im Einsatz für eine Weile in der Popularität Jahre später zurück.
"Ceteris paribus, Sie würden erwarten, dass jedes Wort die gleiche Popularität von Jahr zu Jahr, würde", sagte Joel Tenenbaum, ein Physiker an der Boston University und ein Co-Autor des Papiers.
Die Wissenschaftler fanden heraus, dass der Wortschatz einer Sprache wuchs, ein Wort Popularität immer weniger, bis zur Neuzeit ändern würde wo die beliebtesten Wörter seit Jahrzehnten konstant geblieben sind. Es war nicht nur Englisch, das "", abgekühlt wie es wuchs.
"In der Zeitung finden wir diese überwältigende Trend in allen Sprachen,", sagte Petersen.
Linguisten waren viele der Schlussfolgerungen von den Forschern in der Gemeinschaft bekannt.
"sie haben einige der größten Skala-Arbeit, die jemand jemals getan hat, getan", sagte Bill Kretzschmar, Linguist an der University of Georgia. Allerdings nannte er ihre Ergebnisse underwhelming. "Für jeden Millionen Wörter, die Sie hinzufügen, nach den ersten paar Sie nicht bekommen, viel davon Rückkehr, und wir schon wussten."
Petersen geantwortet, dass Ihnen der erste Versuch war, genau, wie viel eine Sprache "kühlt" zu quantifizieren, da es erweitert.
Kretzschmar, sagte, dass er froh sei, dass Physiker und Mathematiker in Linguistik zu interessieren begannen. Er sagte, dass die statistischen Techniken, die Forscher auf dem Gebiet potenziell neue Erkenntnisse bringen könnte.
"sie bringen Modelle und Methoden, die ich nicht habe," sagte Kretzschmar. "Ich denke, dies ist eine wichtige Bewegung in der Studie der Sprache."
Er fügte hinzu, dass die Weite des Google-Bibliothek bedeutet, dass Sachbücher, Belletristik, Lyrik Bücher und Zeitschriftenartikel wurden alle in der gleichen Datenbank zusammengeführt. Dies stellt ein Problem dar, da diese verschiedenen Formen der schriftlichen Kommunikation dramatisch in ihrem Gebrauch von Sprache, variieren wie z. B. in ihrem Niveau der Formalität, direkte Vergleiche erschwert.
"Da gibt es eine ähnliche Mischung von Jahr zu Jahr, sind wir nicht Äpfel mit Birnen vergleichen. Wir einen Korb mit Äpfeln und Orangen zu noch einem Korb von vergleichbaren Teilen von Äpfel mit Birnen vergleichen,", sagte Petersen. Google bricht einige ihrer englischen Texte in Unterkategorien wie britisches Englisch, amerikanisches Englisch und Englische Fiktion. "Wir fanden die gleichen Muster unabhängig welche Google-Datasets verwendet wir."
Kretzschmar bemängelt auch Googles Metadaten als manchmal ungenau. Es enthält Informationen über das gescannte Bücher wie ihre Erscheinungstermine, Autor und Verleger. Darüber hinaus trotz Computern oft Briefe bei der Interpretation einer gescannten Seite. Google wird es als ein neues Wort zu lesen, aber eigentlich es nur ein Rechtschreibfehler ist.
Petersen sagte das war eine bekannte Schwachstelle in ihrer Arbeit, und sie arbeiteten auf eine verbesserte Möglichkeit, Fehler zu beschneiden.
Mike Lucibella ist Co-Autor für innen Wissenschaft-News-Service.
In Science News Service wird unterstützt durch das American Institute of Physics.

Aufstieg und Fall der Feuerwehrmann Stange
Aufstieg und Fall der großen Weltstädte: 5.700 Jahre der Urbanisierung – zugeordnet

Aufstieg und Fall der DuckFace: Fügen Sie einfach Spaghetti
Schlagen die Flasche: der Aufstieg und Fall der beschwipsten Mama Blogger

Imbiss nach unten: Der Aufstieg und Fall der Super-Bowl-Snacks

Coriolanus am National Theater Live: Schneiden Sie den Chat und wieder mit der Show

David Byrne musikalische hier liegt Liebe Charts Aufstieg und Fall von Imelda Marcos

Erleben Sie den Aufstieg einer amerikanischen Legende. Einige Montage erforderlich.

Weisheit von Mutter Blogger: wie Sie tun, ziehen Sie den Netzstecker und nehmen Sie eine Auszeit vom Bloggen?

Physiker entdecken Sie Geheimnisse der Anhörung Seufzer und flüstert

Aufstieg und Fall von Sarah Palin: gerupft Weg von Alaska, sie verloren ihre Seele
Beratung durch eine Bühne-Mutter mit einem schönen Baby Erziehung. Babble hat eine Mutter Geschichte von Baby Modellierung und wie vermeiden sie den Festzug Mutter Fluch der Hubschrauber Elternschaft.

Der Aufstieg und Fall (und Aufstieg) ASCII-Art
