Erkennen von sozialen Mustern verschieben Dialekte

Behind the Scenes Artikel wurde LiveScience in Zusammenarbeit mit der National Science Foundation zur Verfügung gestellt.
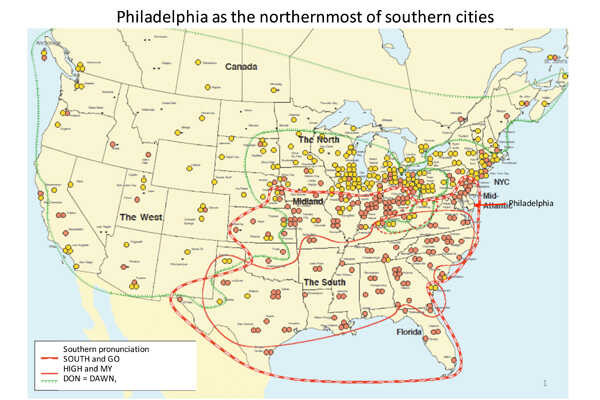
Blicke können einen Raum punktieren, wenn Hörer die Linie hören zu wissen, "You say Tomate, ich sage Tomahto," aus dem beliebten Gershwin Song "nennen wir das ganze aus." Egal, ob Sie aus Fresno, Winnetka, Philadelphia oder Waco, identifiziert Sie Ihren Dialekt oft mit einem bestimmten Gebietsschema.
Jetzt mit einem leistungsfähigen Computer-Programm, Einblicke Forscher an der University of Pennsylvania in eine signifikante Veränderung im Dialekt des Philadelphier. Rechtzeitig ein Jahrhundert verlagerte sich der Klang von Philadelphia aus einem etwas südlichen Akzent zu einem nördlicheren. Und es ist nicht nur ein paar Bereiche von Philadelphia. Die ganze Stadt verlagert. "Die Umkehr zeigt große Veränderungen in den sozialen Mustern," sagt University of Pennsylvania Linguist William Labov.
Als die nördlichste der südlichen Städte, hat Philadelphia weiterhin Fortschritte in Richtung einer nördlicheren klingende Dialekt. "All diese Dinge, die Philadelphia mit dem Süden ausgerichtet verschwinden", sagt Labov. "Im Süden zurückweichen und Sprache ist sehr empfindlich auf tiefgreifende gesellschaftliche Einstellungen." " Jüngere Menschen sind weniger wahrscheinlich zu holen oder südlichen Beugungen zu verwenden.
"Wenn wir untersuchen, wie sich Sprache verändert, wir gewinnen einen Überblick was wir als menschliche Wesen sind", sagt Labov. "
Regionale Dialekte in Amerika sind immer mehr verschiedene und jeder Region Weg von den anderen."
Ein Vokal zu einem Zeitpunkt
Labov und seinen Kollegen entwickelt ihre Schlussfolgerungen mit einem Programm namens gezwungen Ausrichtung & Vokal Extraktion (FAVE). Es erlaubt ihnen automatisch Vokale auf Aufnahmen von Interviews mit Referenten aus 89 Nachbarschaften in der ganzen Stadt analysieren deren Geburtsjahre von 1888 bis 1991 reichte. Die Interviews wurden jährlich Anfang 1973 als Teil einer langfristigen Sprache Studie von Labov und seinen Schülern zusammengestellt.
"Wir wollten automatische was, machen in der Vergangenheit war ein quälend langsam Hand-Prozess" sagt Labov von Computer-Analyse-Programm. Zuvor erforderlich Vokal Analyse, eine digitale Aufzeichnung auf einem Computer anhören und körperlich stoppen den Ton um eine Messung eines Vokals klingen zu lassen. Die wenigen automatisierten Analyseprogramme, die erforderliche Qualität überprüft um festzustellen, ob das Programm korrekt, Anfang und Ende von einem Vokal identifiziert hatte.
"Als der ursprüngliche Algorithmus korrekt, sehr arbeitet wurden einige Fehler gefunden. Jedoch wenn es ausgeschaltet war, es war durch viele und zahlreiche Fehler eingeführt", sagt Josef Fruehwald, arbeiten mit Labov Doktorand. Ältere Programme waren auch nicht in der Lage, genau durch die Nebengeräusche eingeführten Haushalt Geräusche wie Wasser oder einen Fernseher im Hintergrund auf den Aufnahmen zu sortieren.
Zwei Jahre in der Herstellung der FAVE Programm folgt jedes Wort auf eine Interview-Abschrift und schaut auf die jedes Wort klingt in einer Aussprache-Wörterbuch. Für das Wort "Fledermaus", zum Beispiel der Algorithmus markiert den Anfang und das Ende von b, a, und t. Es liefert dann Analyse für Vokale während des gesamten Interviews. Das Programm ist so effizient, dass in einer Stunde freuen Sie 7000 Messungen für ein Interview. Vor FAVE könnte eine Analyse dauert 3 Tage und nur 300 Messungen ergeben.
"Das Programm hat wirklich explodierte das Volumen der Daten erhalten wir von jeder Lautsprecher", sagt Fruehwald. Die Forscher haben rund 1 Million Vokale in der Studie gemessen. Die erhöhte Daten verbessert die Genauigkeit der Sprachanalyse und bietet ein höheres Maß an Vertrauen in die Ergebnisse.
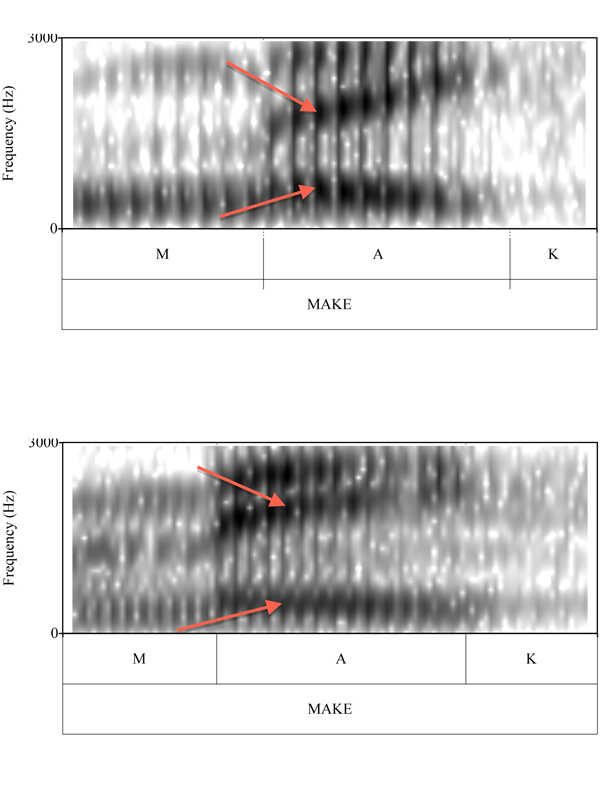
Verschieben von Daten
Eine große Datenmenge in einer sinnvollen Weise zu präsentieren wurde für Fruehwald an erster Stelle. So schuf er Bewegung Abbildungen wie Vokal in der Studie, die im Laufe der Zeit geändert klingt. Ein Datenpunkt im Diagramm für die "aw" Ton, zum Beispiel bewegt sich in eine südlichere Aussprache seit über 75 Jahren und wendet sich dann wieder in eine nördlichere Aussprache.
Fruehwald, sagt, dass die Software ein größeres Publikum durch eine wachsende Zahl von Verwandten Vorträge auf Fachkonferenzen finden ist. "This is gonna alle abnehmen werden", sagt Fruehwald. Linguisten, die Interesse an der Nutzung der FAVE Suite können herunterladen oder verwenden Sie das Online-Interface kostenlos am Standort FAVE.
Das Endergebnis
Wie die hier untersuchten bleiben ein großes Hindernis für Kommunikation, vor allem wenn es um Maschine Anerkennung von Spontansprache wandelt. Unternehmen bei der Schaffung von Rede Anerkennungsprogramme habe zur der Atlas of North American English, produziert von Labovs Forschungsgruppe, definieren den Bereich der Dialekte, die dargestellt werden, müssen in der Datenbank von Klängen die Spracherkennungs-Software "trainiert". Philadelphia Lehrer benutzen auch das Ergebnis der Gruppe, um ihre Klassenzimmer Pläne zu verfeinern, so dass sie Rede Variationen unter den Studierenden ausmachen.
Zukünftige Forschung von Labov Team beinhaltet lernen warum Akzente in allen der Studie Nachbarschaften in die gleiche Richtung zur gleichen Zeit bewegt und wie Minderheitsbeteiligung wirkt sich verändernden Dialekt Muster.
Editor ist zu beachten: Die Forscher in Behind the Scenes Artikel dargestellt wurden unterstützt durch die National Science Foundation, der Bundesagentur mit der Finanzierung von Grundlagenforschung und Ausbildung in allen Bereichen der Wissenschaft und Technik beauftragt. Meinungen, Erkenntnisse und Schlussfolgerungen oder Empfehlungen ausgedrückt in diesem Material sind die des Autors und spiegeln nicht unbedingt die Ansichten von der National Science Foundation. Sehen den Blick hinter die Kulissen Archiv.

Autistischen Gehirn zeichnet sich bei erkennen von Mustern
Ihre brillante Baby in Woche 6: erkennen von Mustern

"Facebook-Depression": seltene, aber schwerwiegende Nebenwirkung von sozialen Netzwerken
Tasmanische Teufel wird abgewischt Out von sozialen Bindungen

Wir sind langsam geschraubt, von sozialen Netzwerken und wir sind blind

Liberalen Extra von zentralen Casting gibt Einblick in Wirklichkeit Turnbull Show

Mörder von Schulmädchen Kayleigh Haywood, mindestens 35 Jahre zu dienen

4 Möglichkeiten, um Ihr Kind zu Spitzenleistungen führen | Kind-Leistung | Verhalten von Kindern

Maschinen spürte die Erdbeben in Nepal von 8.000 Meilen entfernt

5 Wege, die Sie nicht erkennen, dass die englische Sprache ist defekt

Die professionelle Hoax-Trolle von St. Petersburg

Bande von juveniler Dinosaurier entdeckt

Hirnregion schaltet in sozialen Situationen
